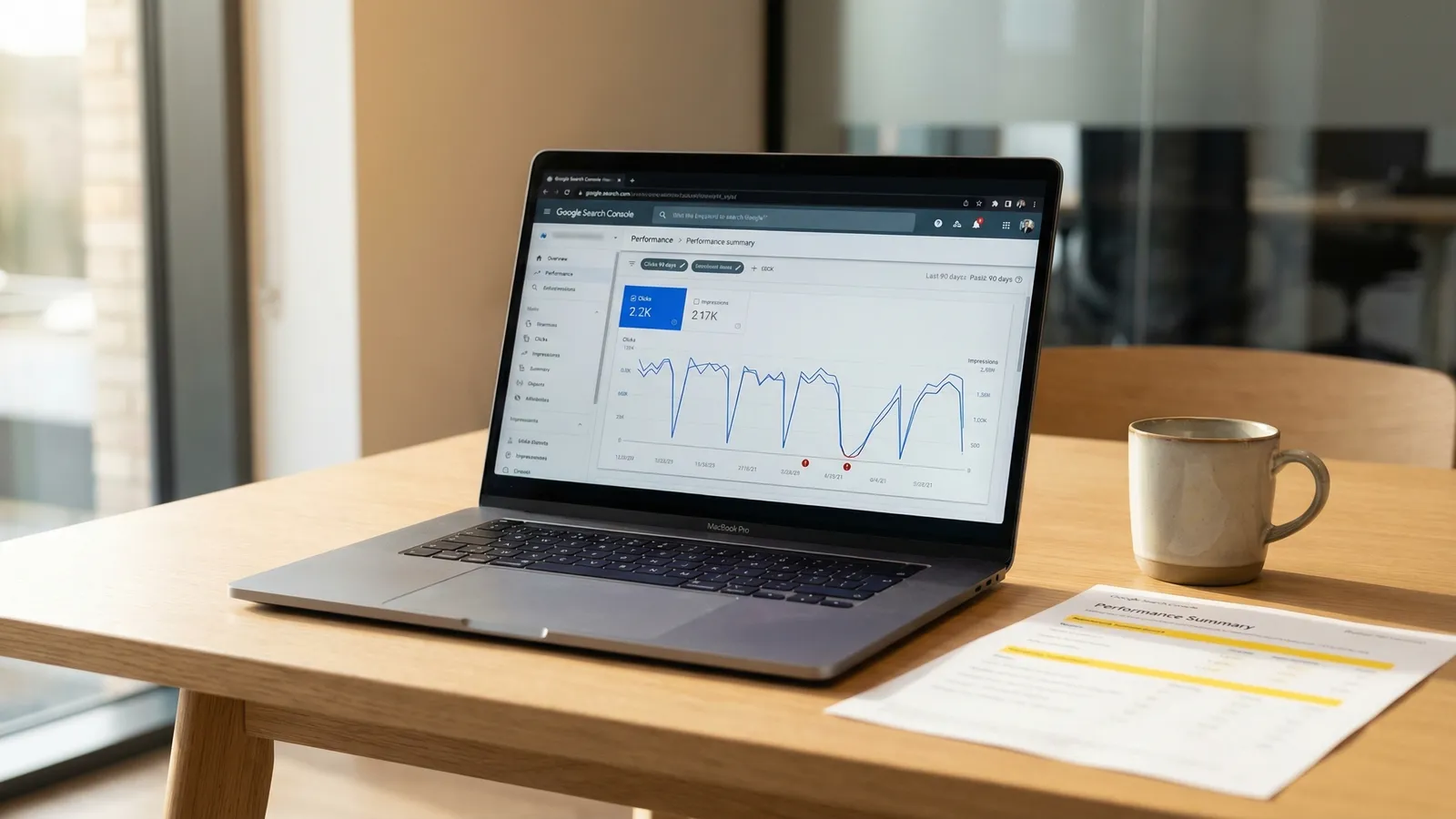
OtterlyAI published a 90-day experiment on 5 February 2026 tracking AI crawler behaviour on a site with an llms.txt file. The result: only 84 out of 62,100 AI bot requests (0.1%) touched the file. A separate SE Ranking study of nearly 300,000 domains found zero correlation between having an llms.txt file and being cited by AI. Both studies concluded the same thing: llms.txt has no measurable effect on AI visibility.
They're both right about the data. And both wrong about what it means.
What the Studies Actually Measured
The OtterlyAI experiment tracked server logs for 90 days, filtering for AI-branded user agents. Of the 62,100+ AI bot visits their site received, just 84 went to /llms.txt. The average content page got about 265 AI visits. Their llms.txt performed three times worse than a typical page on the site.
SE Ranking took a bigger swing. They analysed 300,000 domains using an XGBoost machine learning model to predict AI citation frequency. When they removed llms.txt as a variable from the model, accuracy actually improved. The file was adding noise, not signal.
Google's John Mueller piled on. In a Reddit comment reported by Search Engine Journal, he compared llms.txt to the discredited keywords meta tag: "Is the site really like that? Well, you can check it. At that point, why not just check the site directly?"
Case closed? Not quite.
They Measured the Wrong Thing
Both studies measured whether AI crawlers visit the file. That sounds reasonable until you read what llms.txt was actually designed to do.
Jeremy Howard, the creator of the llms.txt specification, wrote it for one specific purpose: inference-time retrieval. In his own words: "Our expectation is that llms.txt will mainly be useful for inference, i.e. at the time a user is seeking assistance."
Not crawling. Not indexing. Not ranking. The file exists so that when someone asks an AI "tell me about this business," the AI can pull a concise, structured overview rather than parsing thousands of HTML pages.
Measuring crawler visits to llms.txt is like judging a restaurant menu by counting how many delivery drivers read it. The menu is for diners. The file is for inference.
The Quality Gap Nobody Tested
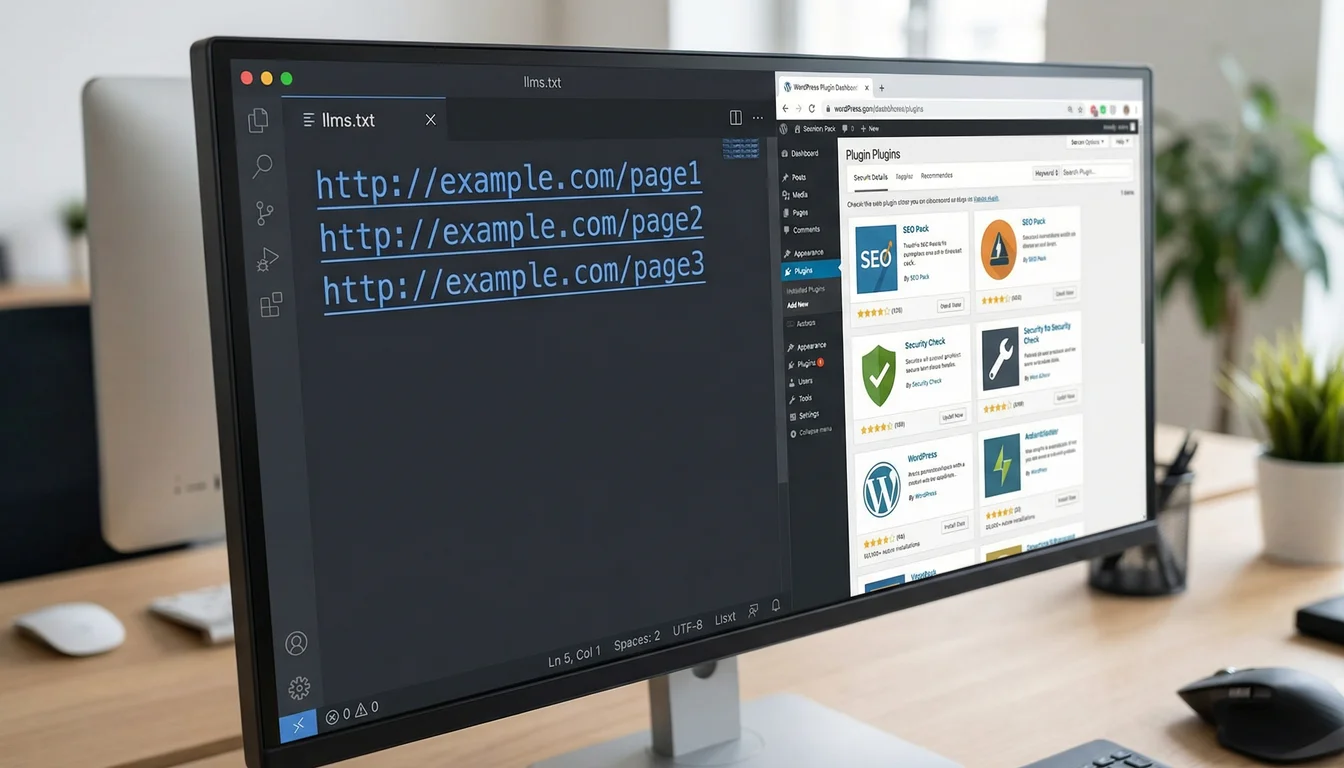
Here's what neither study examined: what was actually inside the llms.txt files they tested?
SE Ranking treated llms.txt as a binary variable across 300,000 domains. Has the file: yes or no. They never looked at the content of a single one. Given that the vast majority of implementations are auto-generated URL dumps from WordPress plugins and SEO tools, the study effectively tested whether auto-generated sitemaps improve AI citations.
Of course they don't. AI already has your sitemap.
OtterlyAI tested their own site. I checked their llms.txt file. It's a hybrid technical document packed with format specifications, caching instructions, and references to optimised model names. It reads like a crawler instruction manual, not the "concise, expert-level information" that Howard's specification describes.
The specification is explicit about quality. It calls for:
- An H1 heading with your project or business name
- A blockquote summary with key context
- Brief, informative descriptions (not URL lists)
- Testing with actual language models to verify they can answer questions about your content
How many of those 300,000 implementations met that standard? Nobody checked. Nobody even asked. Our Q1 2026 adoption research across 1,460 top websites finally ran those quality checks: 56% of AI Discovery Files fail validation entirely. It's the same pattern we see in writing, where people dismiss clear prose as AI-generated without reading what it actually says.
Two Completely Different Approaches

People implement llms.txt in two ways, and they're so different they shouldn't share a name.
The sitemap approach: A list of URLs pointing to your pages, posts, and products. This is what WordPress plugins generate by default. It duplicates your sitemap.xml in markdown format. AI crawlers already have this information. Adding it again in a different file format achieves precisely nothing.
The identity approach: A structured document explaining who your business is, what it does, what makes it different, and where an AI can verify those claims. It includes context that doesn't exist on any single page of your website: your service areas, your specialisms, your accreditations, and the questions customers actually ask.
When OtterlyAI says llms.txt "performed well below a typical page," they're describing what happens when a file adds no information the AI doesn't already have. When Carolyn Shelby, Principal SEO at Yoast, pushed back on the keywords meta tag comparison, she drew the right distinction: llms.txt "guides models to actual value, not self-declared relevance," but only if the content behind it has substance.
We covered this distinction when Google and Bing flagged the difference between content mirrors and identity files. Mueller and Fabrice Canel are right that duplicating your website content in markdown is pointless. They're wrong if they think that's all llms.txt does, because that's not what the specification asks for.
llms.txt Was Never an SEO Tool
This is where the entire conversation goes sideways. Every study, every article, and every dismissal evaluates llms.txt against SEO metrics. Does it improve rankings? Does it increase citations? Does it drive more crawler activity?
It was never designed to do any of those things.
Howard's specification says it clearly: the file is for "inference-time assistance." When a user asks ChatGPT about a plumber in Kettering, and ChatGPT needs to understand that business quickly within its token window, a well-written llms.txt gives it the answer in one file instead of parsing an entire website.
Google's Gary Illyes confirmed in July 2025 that Google "doesn't support llms.txt and isn't planning to." Fair enough. Google has its own content extraction pipelines. But Google isn't the only AI system that matters. And even OtterlyAI's Thomas Peham called the file "integration-focused" rather than a search tool, which is exactly the argument for treating it as an identity document rather than an SEO lever.

The Evidence Everyone Ignores
Not all the data points to zero. An independent experiment by Alimbekov showed a 23% increase in AI chat traffic over four months after implementing llms.txt, with Perplexity nearly doubling its visits. It was a smaller, personal site, not a 300,000-domain survey. But nobody in the mainstream coverage has investigated why this outlier exists.
Then there's the crawling data. SEO professional Ray Martinez reported in July 2025 that OpenAI's crawlers were hitting llms.txt every 15 minutes on several sites. That contradicts Mueller's claim that "none of them fetch the llms.txt file." At least one major AI provider is reading these files, and doing so with considerable frequency.
Crystal Carter, Head of SEO Communications at Wix, reviewed over 1,400 llms.txt files and found "demonstrable evidence that llms.txt files are being surfaced on a number of AI and search platforms." She also noted they require a fraction of the tokenisation cost of a standard web page, making them "well suited to the agentic era."
And then there's Google itself. In December 2025, Google briefly added an llms.txt file to its own Search Central documentation before removing it the same day. SEO professional Lidia Infante spotted it and asked: "Is this an endorsement of llms.txt or are you trolling us, John?" Mueller's response: "hmmn :-/". Whatever is happening internally at Google, it isn't as settled as the public dismissals suggest.
What Actually Makes llms.txt Work
If you're implementing llms.txt as a URL list, stop. You're wasting your time. The studies are right about that. But if you're writing a proper business identity document, here's what belongs in it:
| Include (Identity) | Leave Out (Sitemap) |
|---|---|
| Business name, location, service area | Lists of page URLs |
| What you do and who you serve | Product catalogue links |
| Your specialisms and qualifications | Blog post archives |
| How your service works (process) | Format specifications |
| Common customer questions with answers | Technical caching instructions |
| Facts an AI can verify (accreditations, awards) | SEO keywords or meta descriptions |
The test is simple: does your llms.txt contain information that AI can't get by crawling your homepage? If the answer is no, you have a sitemap in disguise. If yes, you have something worth having.
We've published a practical guide to how AI discovery files help businesses get recommended, and our own llms.txt runs to 228 lines of structured business context. It tells AI who we are, what we do, which industries we serve, and how our process works. None of that information exists on any single page of our website. It's context that only a curated document can provide.
One File Isn't Enough
Every study evaluates llms.txt in isolation. But a single file on its own is weak regardless of quality. The real value comes from a suite of AI discovery files working together:
- llms.txt provides the business identity overview
- ai.txt declares usage permissions for AI systems
- identity.json gives AI structured, machine-readable entity data
- brand.txt tells AI how to represent your brand correctly
- faq-ai.txt provides verified question-and-answer pairs
Together, these create a structured identity framework that crawling alone can't replicate. We tested this directly with what Google Gemini extracts from a properly written set of AI discovery files, and the difference between a site with these files and one without was substantial.
97 out of 100 UK small businesses we tested were invisible to ChatGPT. None of them had AI discovery files. The businesses that were visible had structured, verifiable information that AI could confidently cite. That's the gap these files fill.
What UK Businesses Should Do
Don't implement llms.txt because an SEO plugin told you to. Don't skip it because a study said it has zero impact. Do this instead:
- Write a proper business identity document. Not a URL list. Not a sitemap in markdown. A clear, structured explanation of who you are, what you do, and where you operate. If a plumber asks ChatGPT about boiler services in Northampton, your llms.txt should give the AI everything it needs to recommend you accurately.
- Test it. Paste your llms.txt into ChatGPT or Claude and ask: "Based on this file, what does this business do and who should use it?" If the AI can't answer, rewrite it.
- Don't stop at one file. Implement the full suite: ai.txt, identity.json, brand.txt, faq-ai.txt. The llms.txt specification is one piece of the puzzle.
- Stop measuring it with SEO metrics. The question isn't "did my rankings improve?" It's "can AI accurately describe my business when a customer asks?"
- Check what AI actually says about you. Use the AI Visibility Checker to see how ChatGPT and other AI systems represent your business today. That's the baseline you're working from.
The cost of doing this properly is near zero. The downside of a bad implementation is equally zero, which is exactly what the studies measured. But a good implementation gives AI the structured context it needs to recommend your business with confidence. No study has tested that yet. The AI Discovery Files Directory is the first registry that verifies implementation quality, not just file presence. Free listings are open now, with dofollow backlinks and an AI visibility score for every verified site.
Frequently Asked Questions
Does llms.txt improve SEO rankings?
No. llms.txt was never designed as an SEO tool and Google has confirmed it doesn't use the file for ranking. Two independent studies (OtterlyAI and SE Ranking) found zero correlation between having an llms.txt file and improved search visibility. The file's actual purpose is inference-time context for AI assistants, not search engine optimisation.
What did the OtterlyAI llms.txt study find?
OtterlyAI monitored AI crawler behaviour for 90 days and found that only 84 out of 62,100 AI bot requests (0.1%) accessed their llms.txt file. They concluded the file had "negligible AI crawler interest" and was "not a GEO lever." The study measured crawler visits rather than inference-time usage, which is what the specification was designed for.
Why do most llms.txt implementations fail?
Most implementations are auto-generated URL lists from WordPress plugins or SEO tools. They duplicate what AI already gets from crawling your sitemap. The llms.txt specification calls for concise, expert-level business context: who you are, what you do, who you serve. A file that adds no new information produces no new results.
Do any AI systems actually read llms.txt?
Yes. OpenAI's crawlers have been observed hitting llms.txt files every 15 minutes on some sites. Crystal Carter at Wix found evidence of llms.txt content being surfaced across multiple AI platforms. Google has said it doesn't use the file, but other AI providers appear to be reading and using them.
What should a good llms.txt contain?
Your business name, location, and service area. A clear description of what you do and who you serve. Your specialisms and qualifications. Common customer questions with answers. Facts an AI can verify, like accreditations and awards. Do not include URL lists, product catalogues, blog archives, or technical caching instructions.
Is llms.txt the same as the keywords meta tag?
Google's John Mueller compared them, but Carolyn Shelby at Yoast argued there's a key difference: the keywords meta tag contained unverifiable claims, while llms.txt points to real content that "has to exist and deliver when the model gets there." A properly implemented llms.txt guides AI to verifiable information rather than making empty declarations.
Should my business implement llms.txt?
Yes, but only if you write it properly. A URL dump will do nothing, as the studies confirm. A structured business identity document costs nothing to create and gives AI systems the context they need to represent your business accurately. Implement it as part of a full suite of AI discovery files (ai.txt, identity.json, brand.txt, faq-ai.txt) for the best results.
How can I test if my llms.txt is working?
Paste the contents of your llms.txt into ChatGPT or Claude and ask: "Based on this, what does this business do and who should use it?" If the AI gives an accurate, specific answer, your file is working as intended. If it can't answer or gives a vague response, rewrite the file with more business context. Also use an AI Visibility Checker to see how AI systems currently represent your business.
Find Out What AI Says About Your Business
The studies measured the wrong thing. The real question is whether AI can accurately describe your business when a customer asks. Check your AI visibility now.
Check Your AI VisibilitySources
- The llms.txt Experiment: Results from OtterlyAI's GEO Study - OtterlyAI
- LLMs.txt: Why Brands Rely On It and Why It Doesn't Work - SE Ranking
- The llms.txt Specification - Answer.AI
- No, llms.txt Is Not the 'New Meta Keywords' - Search Engine Land
- How llms.txt Increased AI Chat Traffic by 23% - Alimbekov
- OpenAI Crawling llms.txt Files Every 15 Minutes - Search Engine Roundtable