Anthropic released Claude Sonnet 4.6 yesterday. OpenAI's GPT-5.2 has been live since December. Google's Gemini 3 Pro shipped in November. For the first time, all three major AI platforms are running new-generation models at the same time, and they're close enough in capability that the choice between them actually matters.
I use all three. Every day. Claude Code builds this website. GPT-5.2 handles maths-heavy analysis. Gemini processes documents at scale. After months of hands-on work with each of them, I can tell you the benchmarks don't tell the full story. The right model depends entirely on what you're trying to do.
Here's the comparison nobody else is writing: not which model "wins" overall, but which one you should use for each specific task, with real numbers, real pricing, and real UK business context.
The Benchmarks That Actually Matter
Every AI company publishes benchmarks that make their model look best. Anthropic leads with GDPval. OpenAI highlights AIME mathematics. Google points to GPQA Diamond. So let's put the numbers that matter most in one place.
| Benchmark | Claude Sonnet 4.6 | GPT-5.2 | Gemini 3 Pro |
|---|---|---|---|
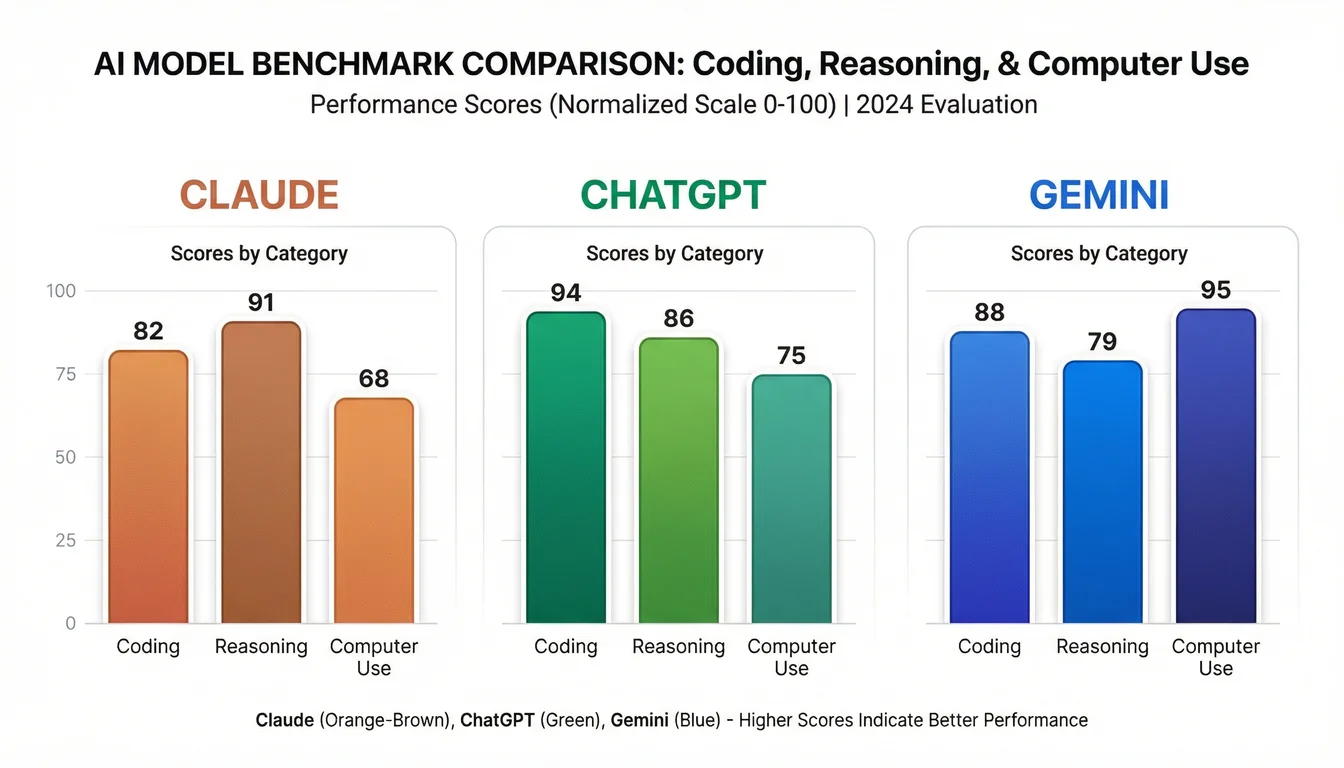
| SWE-bench Verified (coding) | 79.6% | 80.0% | 76.2% |
| OSWorld (computer use) | 72.5% | 38.2% | N/A |
| GDPval-AA Elo (knowledge work) | 1633 | 1462 | N/A |
| Finance Agent v1.1 | 63.3% | 59.0% | N/A |
| ARC-AGI-2 (general intelligence) | 60.4% | N/A | N/A |
| GPQA Diamond (science reasoning) | N/A | 93.2% | 93.8% |
| Context Window | 1M tokens | 400K tokens | 1M tokens |
| Max Output | 128K tokens | 32K tokens | 64K tokens |
The numbers look tidy in a table. In practice, though, what matters is how each model behaves when you're actually working with it. And that's where the story gets more interesting.
A quick note on these benchmarks: N/A entries don't mean the model fails at that task. They mean the company hasn't published an official score for that specific test. Google and OpenAI run different benchmark suites from Anthropic, so direct comparison isn't always possible.

Coding: Who Builds Better Software?
This is where I have the strongest opinion, because I write code with AI every single day.
Claude Sonnet 4.6 scores 79.6% on SWE-bench Verified, nearly identical to its big brother Opus 4.6 at 80.8%. That's remarkable for a model that costs a fifth of the price. In Claude Code, early testing found users preferred Sonnet 4.6 over the previous Sonnet 4.5 roughly 70% of the time. And here's the part that caught my attention: users preferred Sonnet 4.6 over the previous flagship Opus 4.5 in 59% of comparisons. A mid-tier model outperforming last generation's top-tier model is a shift.
GPT-5.2 hits 80.0% on SWE-bench Verified, technically the highest of the three. But the gap is 0.4 percentage points. In daily use, that difference vanishes. Where GPT-5.2 pulls ahead is on Terminal-Bench 2.0, the command-line coding benchmark, where it scores 64.7% (Sonnet 4.6 isn't separately benchmarked here, though Opus 4.6 leads at 65.4%).
Gemini 3 Pro scores 76.2% on SWE-bench, solid but behind the other two. Where Gemini shines in coding is speed: 134 tokens per second output means it generates code faster than either competitor. If you're prototyping rapidly and need quick iterations, that speed advantage adds up.
Best coding AI: Claude for production code (fewer bugs, better instruction-following). GPT-5.2 for complex algorithmic work. Gemini for rapid prototyping where speed matters more than precision.
I've written about how Claude Opus 4.6 changes web design workflows. Sonnet 4.6 delivers most of that capability at a fraction of the cost, which changes the calculus for smaller projects.

Writing and Content: Who Writes Better?
This section is going to be blunt. OpenAI's CEO publicly admitted they got it wrong.
Sam Altman acknowledged in January that OpenAI "screwed up" GPT-5.2's writing quality by prioritising coding and mathematics over prose. Users reported the model was "unwieldy" and "hard to read." The technical focus came at the expense of natural language. OpenAI then retired five older models (including GPT-4o, which many users preferred for writing) on 13 February, leaving GPT-5.2 as the only option in ChatGPT.
That's a problem if your business relies on AI for content creation, email drafts, social media, or customer communications.
Claude Sonnet 4.6 doesn't have this problem. Anthropic has consistently prioritised writing quality alongside technical performance. The model follows instructions more precisely, avoids overengineering prose, and produces output that reads like a human wrote it. In my testing, it also handles UK English better than either competitor (colour, optimise, defence; not color, optimize, defense).
Gemini 3 Pro sits somewhere in between. Its writing is competent but tends toward verbosity. The model generates more tokens than necessary for most tasks, which inflates costs if you're paying per token through the API. For short-form content and summaries it's fine. For long-form articles where voice and tone matter, Claude has the edge.
"We believe Claude excels at producing nuanced, human-sounding text, making it particularly well-suited for content creation, customer communication, and business writing tasks."
Anthropic, Claude Sonnet 4.6 announcement, February 2026
I use Claude for everything I publish. This article, every post on this site, every social update. Not because it's perfect, but because it follows direction better than the alternatives. When I say "UK English, conversational, no corporate waffle," it listens. GPT-5.2 still defaults to American English and formal phrasing unless you fight it on every prompt.
Best writing AI: Claude for business content, blog posts, and anything requiring a specific voice. GPT-5.2 for technical documentation (its analytical strength compensates for weaker prose). Gemini for high-volume summarisation tasks where style matters less.

Computer Use and Agents: Who Gets Work Done?
This is the category that matters most for where AI is heading. Computer use means the AI can control your mouse, click buttons, fill forms, navigate websites, and complete multi-step tasks without human intervention.
The gap here isn't close.
Claude Sonnet 4.6 scored 72.5% on OSWorld-Verified, the standard benchmark for AI computer use. That's up from 14.9% when Anthropic first launched this capability sixteen months ago. To put it plainly: Claude went from barely functional to near human-level on complex tasks like navigating spreadsheets, filling insurance forms (94% accuracy), and completing multi-step web workflows. Sonnet 4.6 matches Opus 4.6 here (72.7%), which means you get top-tier agent performance at Sonnet pricing.
GPT-5.2 scored 38.2% on the same benchmark. Less than half of Claude's score. OpenAI has invested more heavily in reasoning and mathematics than in agentic capabilities, and it shows. Their Codex product handles autonomous coding well, but general computer use lags behind.
Gemini 3 Pro powers Chrome's auto-browse feature, which lets AI navigate websites and complete tasks on your behalf across 3 billion Chrome installations. Google's approach is different: rather than benchmarking against OSWorld, they've integrated agents directly into the browser. For AI Overviews, Gemini 3 already reaches over a billion users.
If you're building AI agent workflows for your business, Claude is currently the strongest foundation. If you care about how AI agents interact with websites as visitors (which affects your business visibility), Gemini's browser integration matters more.
Best agent AI: Claude for custom agent workflows and autonomous task completion. Gemini for browser-based agent interactions. GPT-5.2 for reasoning-heavy agent chains where the agent needs to think deeply rather than act quickly.

Pricing: What Does Each Actually Cost?
Pricing is where businesses often get tripped up. The per-token cost is only half the picture; what matters is the cost per useful output.
| Model | Input Cost | Output Cost | Approx. GBP per 1M Output |
|---|---|---|---|
| Claude Sonnet 4.6 | $3.00 | $15.00 | ~£12.00 |
| Claude Opus 4.6 | $5.00 | $25.00 | ~£20.00 |
| GPT-5.2 Thinking | $1.75 | $14.00 | ~£11.20 |
| GPT-5.2 Instant | $0.80 | $3.20 | ~£2.56 |
| Gemini 3 Pro | $2.00 | $12.00 | ~£9.60 |
On raw token price, Gemini 3 Pro is the cheapest for full-capability output at $12 per million tokens. GPT-5.2 Instant is cheaper still at $3.20, but it's a stripped-down model without deep reasoning. GPT-5.2 Thinking is nearly identical to Claude Sonnet 4.6 in output cost ($14 vs $15).
But here's the catch: Gemini 3 Pro is verbose. It generates more tokens per response than Claude, which eats into that pricing advantage. In my testing, a task that produces 500 tokens in Claude often produces 700-800 in Gemini. When you factor in the verbosity, Gemini's per-task cost is closer to Claude's than the per-token numbers suggest.
For consumer plans, ChatGPT Pro costs $200/month (unlimited GPT-5.2 Pro access). Claude Pro costs $20/month (generous usage of Sonnet 4.6 and Opus 4.6). Gemini Advanced costs $19.99/month. For individual professionals, Claude Pro offers the best value by a considerable margin.
Most cost-effective: Claude Sonnet 4.6 for most tasks (near-Opus quality at Sonnet price). GPT-5.2 Instant for simple, high-volume queries. Gemini 3 Pro for batch document processing where the 1M context window saves pre-processing costs.
The smart approach, and what we use at 365i, is model routing. Send complex coding tasks to Claude. Route maths problems to GPT-5.2. Batch document analysis through Gemini. That strategy can cut costs by 70-80% compared to using a single model for everything.

Best Use Cases for Each Model
Stop asking "which AI is best?" Start asking "which AI is best for this specific job?"
Claude Sonnet 4.6: Best For
- Web development and coding. 79.6% on SWE-bench at Sonnet pricing. If you're building websites, apps, or automations, Claude is the tool. I build entire PHP websites with it, from database schemas to CSS animations.
- Business writing and content. Best instruction-following of the three. Handles UK English natively. Doesn't inject corporate jargon unless asked.
- Agent workflows. 72.5% on OSWorld. If you need AI to fill forms, process documents, or complete multi-step tasks autonomously, nothing else comes close.
- Large codebase work. The 1M token context window (beta) means it can hold your entire project in memory. No more "I've lost track of your footer.php" midway through a build.
- Financial analysis. 63.3% on Finance Agent v1.1, leading the pack. For financial modelling, report generation, or data analysis, Claude outperforms both competitors.
GPT-5.2: Best For
- Mathematics and scientific reasoning. 100% accuracy on AIME 2025 mathematics. If your work involves complex calculations, statistical analysis, or scientific data, GPT-5.2 is the strongest choice.
- Knowledge work at expert level. First model to match human experts on GDPval across 44 occupations. For tasks that require domain expertise across multiple fields simultaneously, it excels.
- Reduced hallucinations. OpenAI claims 65% fewer hallucinations compared to GPT-5.1. When accuracy is critical and you can't afford fabricated facts, this matters.
- Technical documentation. Despite weaker prose style, GPT-5.2 produces clear technical specifications and API documentation.
- Budget-sensitive high-volume tasks. GPT-5.2 Instant at $0.80/$3.20 per million tokens is the cheapest capable model available. For customer support routing, classification, or simple Q&A, the cost savings are real.
Gemini 3 Pro: Best For
- Document processing at scale. 1M token context window plus the fastest output speed (134 tokens/second) makes Gemini ideal for processing lengthy contracts, research papers, or compliance documents.
- Multimodal tasks. Gemini processes text, images, video, and audio natively. If your workflow involves analysing visual content alongside text, Gemini handles it seamlessly.
- Google ecosystem integration. Gemini powers AI Overviews, Chrome auto-browse, and soon Siri. If your business needs to be visible where AI meets search, understanding how Gemini works is non-negotiable.
- Science and academic reasoning. 93.8% on GPQA Diamond, the highest of any model. For research-heavy tasks requiring deep scientific understanding, Gemini has a slight edge.
- Rapid prototyping. 134 tokens per second output speed means faster iteration cycles. When you need a working draft in minutes rather than perfection, Gemini's speed is its advantage.
"The smart money uses model routing: Claude for coding-critical and enterprise tasks, GPT-5.2 for complex mathematical reasoning, and Gemini or cheaper models for high-volume, simpler queries."
AI model comparison analysis, Humai.blog, February 2026
That quote matches my experience exactly. The businesses getting the most from AI in 2026 aren't locked into one platform. They route tasks to the right model the same way a good manager delegates work to the right team member. WordPress 7.0 Beta 2 now ships with a Connectors page that lets site owners configure all three providers from a single admin screen, a clear sign the CMS ecosystem is catching up to this multi-model reality.
What This Means for UK Businesses
Most UK small businesses aren't comparing AI models in benchmark tables. They're asking simpler questions: should I use ChatGPT or Claude? Is Gemini worth looking at? Will this save me time or cost me money?
Here's my honest advice after months of using all three in production work.
If you're a sole trader or micro-business, start with Claude Pro at £16/month ($20). You get Sonnet 4.6 as default (which is now near-Opus quality), plus access to Opus 4.6 for the hardest tasks. ChatGPT Pro at $200/month is overkill unless you're doing heavy mathematics. Gemini Advanced at roughly £17/month is solid value but the writing quality won't match Claude's.
If you're running a team, look at API access. Set up model routing: Claude for client-facing content and coding, GPT-5.2 Instant for internal classification tasks, Gemini for batch document processing. One of the articles on the 365i blog covered GPT-5.2's launch in the context of this competitive shift, and the dynamics haven't changed: competition between the three providers is driving quality up and prices down.
If you care about AI visibility, understand that Gemini 3 powers both Google AI Overviews and the upcoming Gemini-powered Siri across 2.5 billion Apple devices. Claude powers business-facing tools and developer workflows. GPT-5.2 powers ChatGPT, which now serves ads alongside organic answers. Your business needs to be visible to all three, and AI discovery files are the fastest way to make that happen.
Anthropic just closed a $30 billion funding round. OpenAI is reportedly valued north of $300 billion. Google's AI investment is embedded across every product they make. These companies aren't going anywhere. The question for UK businesses isn't whether to use AI. It's how to use it wisely, and that starts with choosing the right tool for each job.
Frequently Asked Questions
Which AI model is best overall in February 2026?
There is no single best model. Claude Sonnet 4.6 leads in coding, writing, and agent tasks. GPT-5.2 leads in mathematics and scientific reasoning. Gemini 3 Pro leads in speed, multimodal processing, and Google ecosystem integration. The best approach is using two or three models for different tasks.
Is Claude Sonnet 4.6 good enough to replace Opus?
For most tasks, yes. Sonnet 4.6 scores 79.6% vs Opus 4.6's 80.8% on SWE-bench coding, and 72.5% vs 72.7% on computer use. Users preferred Sonnet 4.6 over the previous flagship Opus 4.5 in 59% of comparisons. At one-fifth the price ($3/$15 vs $5/$25 per million tokens), Sonnet 4.6 is the better choice for the majority of business workloads.
Does GPT-5.2 still have writing quality problems?
Yes. Sam Altman admitted in January 2026 that OpenAI "screwed up" GPT-5.2's writing quality by prioritising coding and maths. Users report the prose is stiff, overly formal, and harder to read than GPT-4.5. OpenAI has promised improvements, but as of February 2026 the writing regression has not been fixed. Claude Sonnet 4.6 is the stronger choice for content creation.
What is the cheapest AI model for UK businesses?
For consumer subscriptions, Claude Pro (£16/month) and Gemini Advanced (~£17/month) are the most affordable. For API use, GPT-5.2 Instant is cheapest at $0.80/$3.20 per million tokens, but it lacks deep reasoning. Gemini 3 Pro ($2/$12) offers the best balance of capability and cost for high-volume tasks. Claude Sonnet 4.6 ($3/$15) is the best value for quality-sensitive work.
Is Gemini 3 Pro better than ChatGPT?
It depends on the task. Gemini 3 Pro is faster (134 tokens/second), has a larger context window (1M vs 400K tokens), and costs less per token. ChatGPT (GPT-5.2) is stronger at mathematics, offers deeper reasoning on complex problems, and has a larger plugin ecosystem. For UK businesses, Gemini matters more because it powers Google AI Overviews and the search results your customers see.
Which AI model is best for web design and development?
Claude Sonnet 4.6. It scores 79.6% on SWE-bench coding benchmarks, has a 1M token context window (enough to hold an entire website project), and its agent capabilities (72.5% on OSWorld) let it complete multi-step development tasks autonomously. Claude Code, Anthropic's developer tool, has become a billion-dollar product largely because of how well Claude handles web development workflows.
Should my business use more than one AI model?
Yes. Model routing, using different models for different tasks, can reduce AI costs by 70-80% while improving output quality. Use Claude for coding and content, GPT-5.2 Instant for simple classification tasks, and Gemini for batch document processing. Most businesses start with one model and add others as they identify specific needs where a different model performs better.
Sources
Is Your Business Visible to All Three AI Platforms?
Claude, ChatGPT, and Gemini are all recommending businesses to users right now. AI discovery files ensure all three know who you are and what you do. Check whether these AI systems can find you.
Check Your AI Visibility